基礎編
はじめに
- RDB(Relational Database)
- 関係データベース
- RDBMS(Relational Database Management System)
- 関係データベース管理システム
- DCL(Data Control Language)
- データ制御言語
- GRANT
- REVOKE
- データ制御言語
- DML(Data Manipulation Language)
- データ操作言語
- SELECT
- INSERT
- UPDATE
- DELETE
- データ操作言語
- DDL(Data Definition Language)
- データ定義言語
- CREATE
- ALTER
- DROP
- データ定義言語
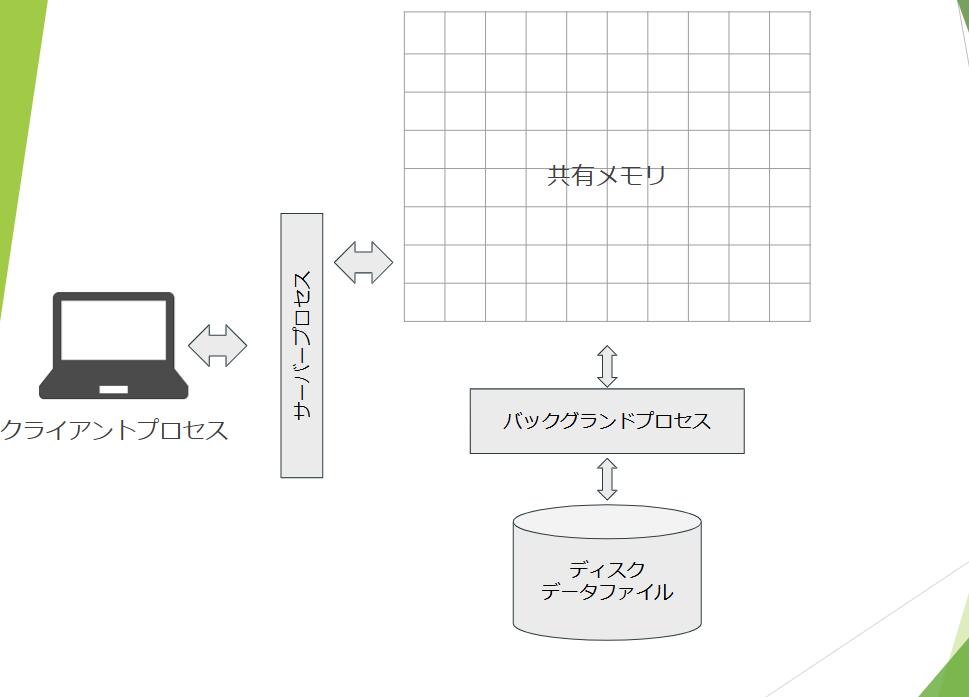
環境構築
まずはインストーラーと、便利ツールを使って始めることを推奨します
学習に使うテーブルを作成するためのSQLです。
Dockerの環境構築も用意してみましたが、初心者にはおすすめしません
アジェンダ
検索テクニック 基礎(単一テーブル)
- 単純なSELECT
- 列を指定
- DISTINCT
- WHERE
- 比較演算子
- LIKE演算子
- 論理演算子
- ORDER BY
- LIMIT
- GROUP BY
- AS キーワード
- 文字列/日付の加工
- HAVING
- CASE演算子(式)
1 単純なSELECT
テーブルから検索するためにはSELECT文を使用します。
Q1:アンケート回答テーブル(quest)から
全てのデータを取得し、その結果を一覧表に出力する。
構文:SELECT 列名 FROM テーブル名;
SELECT
*
FROM
quest
;
Q2:書籍情報テーブル(books)から
全ての列を取り出すSQL文を完成させろ。
[ ① ]
*
FROM
[ ② ]
;
答え
SELECT
*
FROM
books
;
Q3:著者情報テーブル(author)から
全ての列を取り出すSQL文を完成させろ。
SELECT
[ ① ]
[ ② ]
author
;
答え
SELECT
*
FROM
author
;
Q4:月間売り上げテーブル(sales)から
全ての列を取り出せ。
SELECT
*
FROM
sales
;
Q5:書籍情報テーブル(books)から
全ての列を取り出すSQLの誤りを正せ。
SELECT
+
FROM
books
:答え
SELECT
*
FROM
books
;
2 列を指定
Q1:アンケート回答テーブル(quest)から
回答者の名前(name)、性別(sex)、年齢(age)を取得せよ。
構文
SELECT 列名1,列名2,… FROM テーブル名;
SELECT
name,
sex,
age
FROM
quest
;
Q2:書籍情報テーブル(books)から
title列を取り出すSQL文を完成させろ。
[ ① ]
title
FROM
[ ② ]
;
SELECT
title
FROM
books
;
Q3:商品テーブル(product)から
商品名(p_name)と単価(price)を
取り出すSQL文を完成させろ。
SELECT
[ ① ]
[ ② ]
product
;
SELECT
p_name,
price
FROM
product
;
Q4:社員テーブル(employee)から
社員の氏(l_name)、名(f_name)、役職(class)を取り出せ。
SELECT
1,
2,
3
FROM
employee
;
SELECT
l_name,
f_name,
class
FROM
employee
;
Q5:書籍情報テーブル(books)から
title列とpublish列を取り出す
SELECTS
title
publish
FROM
books
;
SELECT
title,
publish
FROM
books
;
3 DISTINCT
テーブルの中には、同じデータが何回も出現することがあります。
例えば、書籍情報テーブルには、isbn、書名、価格、出版社名、出版日、カテゴリーIDがありますが、出版社名や、カテゴリーIDには重複が発生します。
重複を排除して出力することができる命令がDISTINCTです。
SELECT文のデフォルトは、「SELECT ALL」であるためALLを記載しないでも全ての行を出力することができます。
Q1:書籍情報テーブル(books)から
出版社列(publish)を重複なく取得せよ。
SELECT DISTINCT
publish
FROM
books
;
Q2:アンケート回答テーブル(quest)から
都道府県名(prefecture)を重複ない形式で
取り出すSQL文を完成させろ。
SELECT [ ① ]
prefecture
FROM
[ ② ]
;
SELECT DISTINCT
prefecture
FROM
quest
;
Q3:アクセス記録テーブル(access_log)から
リンク元URL(referer)を
重複ない形式で取り出すSQL文を完成させろ。
[ ① ]
referer
[ ② ]
access_log
;
SELECT DISTINCT
referer
FROM
access_log
;
Q4:ユーザーテーブル(usr)から
ユーザ氏名(l_name、f_name)を
重複ない形式で取り出せ。
SELECT DIST
l_name,
f_name
FROM
usr
;
SELECT DISTINCT
l_name,
f_name
FROM
usr
;
Q5:社員テーブル(employee)から
役職(class)を重複ない形式で
取り出すSQL文の間違いを正せ。
SELECT ALL
class,
depart_id
FROM
employee
;
SELECT DISTINCT
class
FROM
employee
;
4 WHERE
テーブルの中には、多くの情報が存在します。
出力するための条件を指定することが可能なのがWHERE句です。
基本的には、カラム名に対して比較演算子を使用して条件を指定します。
この章(4.1~4.3)では、色々な条件の指定方法を学びます。
4.1 比較演算子
| 演算子 | 概要 | 例 |
| = | 等しい | sex = ‘男’ |
| <> | 等しくない | sex <> ‘女’ |
| > | より大きい | age > 20 |
| < | 未満 | age < 20 |
| >= | 以上 | age >= 20 |
| <= | 以下 | age <= 20 |
| [NOT] LIKE | 指定パターンを含む[含まない] | name LIKE ‘山%’ |
| IS [NOT] NULL | NULLである[でない] | name IS NULL |
| [NOT] IN | 候補値の何れかである[ない] | name IN(‘山田’,’山口’) |
| [NOT] BETWEEN | 間である[ない] | age BETWEEN 10 AND 20 |
Q1:アンケート回答テーブル(quest)から
性別(sex)=「女」が解答した結果だけ取得せよ。
取り出す列はname列、 answer1、answer2列とする
SELECT
[ ① ]
FROM
quest
WHERE
[ ② ]
;
SELECT
name,
answer1,
answer2
FROM
quest
WHERE
sex = '女'
;
Q2:アンケート回答テーブル(quest)から
年齢(age)が20歳以上によるanswer1とanswer2列を
取り出すSQL文を完成させろ。
SELECT
[ ① ]
FROM
quest
WHERE
[ ② ]
;
SELECT
answer1,
answer2
FROM
quest
WHERE
age >= 20
;
Q3:書籍情報テーブル(books)から出版社が
「山田出版」「翔泳社」である書籍情報のisbn、title、publish列を
取り出すSQL文を完成させろ。
SELECT
isbn,
title,
publish
FROM
[ ① ]
WHERE
publish [ ② ] (‘山田出版’,’翔泳社’)
;
SELECT
isbn,
title,
publish
FROM
books
WHERE
publish IN('山田出版','翔泳社')
;
Q4:ユーザテーブル(usr)から
東京都に住んでいない人の
l_name、f_name、email列を
取り出すSQL文を完成させろ。
SELECT
l_name,
f_name,
email
FROM
[ ① ]
WHERE
[ ② ]
;
SELECT
l_name,
f_name,
email
from
usr
WHERE
prefecture <> '東京都'
;
Q5:アンケート集計テーブル(quest)から
年齢(age)が30歳以上40歳未満の人の
name、sex、prefecture列を取り出せ。
SELECT
name,
sex,
prefecture
FROM
quest
WHERE
--BETWEENを使った書き方は?
;
SELECT
name,
sex,
prefecture
FROM
quest
WHERE
--答え
age BETWEEN 30 AND 39
;
SELECT
name,
sex,
prefecture
FROM
quest
WHERE
--Andを使った書き方は?
;
SELECT
name,
sex,
prefecture
FROM
quest
WHERE
--答え
age >= 30 AND
age < 40
;
Q6:アンケート集計テーブル(quest)から
解答日時(answered)が”2006/01/01”以降の
name、answer1、answer2列を取り出せ。
SELECT
name,
answer1,
answer2
FROM
quest
WHERE
--2006/01/01以降の条件はどう書けばよいでしょう?
;
SELECT
name,
answer1,
answer2
FROM
quest
WHERE
--答え
answered >= '2006/01/01'
;
Q7:貸し出し記録テーブル(rental)から
貸し出し中のuser_id、isbn列を取り出せ。
--貸し出しが行われたときにレコードが生成され、returned列がデフォルトの0として設定される仕様です。
--貸し出し中は0 返したら1
SELECT
user_id,
isbn
FROM
rental
WHERE
--貸し出し中の条件は?
;
SELECT
user_id,
isbn
FROM
rental
WHERE
--答え
returned = 0
;
Q8:アンケート集計テーブル(quest)から
感想欄が未定義(NULL値)でない
answer2列を取り出せ。
SELECT
answer2
FROM
quest
WHERE
--回答欄が未定義でない条件は?
;
SELECT
answer2
FROM
quest
WHERE
--答え
answer2 IS NOT NULL
;
Q9:書籍情報テーブル(books)から
価格(price列)が5000円未満の
title、publish、price列を
取り出すSQL文の誤りを正せ。
--間違っているところはどこでしょう?
SELECT
title
publish
price
FROM
books
WHERE
price <= 5000
;
--答え
SELECT
title,
publish,
price
FROM
books
WHERE
price < 5000
;
4.2 LIKE演算子
ここまでは、比較演算子を使用して特定の条件に合致したレコードを取り出してきました。
必ずしも厳密に一致したものばかりでなく、あいまいな条件で検索したい場合が多くあります。
例えば、本のタイトルにある文字列を含む(で始まる/で終わる)ような検索です。
この時使用するのが「LIKE演算子」です。
LIKE演算子は一般的には、「~で始まる文字列」を検索するときに使用するように心がけて欲しいです。
RDBMSにおいて検索パフォーマンスを向上させるために使われるものがB-TREEインデックスです。B-TREEインデックスの構造からINDEXが使用されるのは「~で始まる文字列」の検索を行う場合のみです。
Q1:書籍情報テーブル(books)から
書名(title列)にSQLという文字が含まれている、
title、publish、publish_date列を取り出せ。
SELECT
title,
publish,
publish_date
FROM
books
WHERE
--title列にSQLが含まれる条件
;
--ワイルドカード
--[%]:0文字以上の文字列
--[_]:1文字
SELECT
title,
publish,
publish_date
FROM
books
WHERE
--答え
title LIKE '%SQL%'
;
Q2:著者情報テーブル(author)から
名前(name)が「山田」で始まる
著者の全列を取り出すSQL文を完成させろ。
SELECT
[①]
FROM
author
WHERE
--山田で始まる条件は?
;
SELECT
--全列
*
FROM
author
WHERE
--答え
name LIKE '山田%'
;
Q3:アンケート回答テーブル(quest)から
名前が「子」で終わらない人のname列を取り出すSQL文を完成させろ。
SELECT
name
--どこから?
[①]
quest
WHERE
--名前が子で終わらない人の条件?
[②]
;
SELECT
name
--どこから
FROM
quest
WHERE
--名前が子で終わらない
name NOT LIKE '%子'
;
Q4:書籍情報テーブル(books)から
書名が「SQL〇〇」である
isbn、title、price列を取り出せ。(〇は1文字)
SELECT
isbn,
title,
price
FROM
books
WHERE
--書名がSQL〇〇の条件
;
SELECT
isbn,
title,
price
FROM
books
WHERE
title LIKE 'SQL__'
;
Q5:社員テーブル(employee)から
氏(カナ)が「ア」で始まる
l_name、f_namne列を取り出せ。
SELECT
l_name,
f_name
FROM
employee
WHERE
--氏(カナ)が「ア」で始まる?
;
SELECT
l_name,
f_name
FROM
employee
WHERE
l_name_kana LIKE 'ア%'
;
Q6:書籍情報テーブル(books)から
名前が「社」で終わる出版社の書名(title)と
出版社名(publish)を
取り出すSQL分の誤りを正せ。
--誤りを正せ
SELECT
title,
FROM
books
WHERE
publish LIKE ‘_社’;
SELECT
title,
publish
FROM
books
WHERE
publish LIKE '%社'
;
4.3 論理演算子
WHERE句で複数の条件を記述するときに使用することが多いものが論理演算子です。
AND、ORで条件を記述していきます。
ANDとORを使用する場合注意が必要です。
Q1-1:書籍情報テーブル(books)から
isbn、title、publish、price列を取り出せ。
--確認
SELECT
isbn,
title,
publish,
price
FROM
books
;
Q1-2:前のページより
価格が3000円以上の
isbn、title、publish、price列を取り出せ。
SELECT
isbn,
title,
publish,
price
FROM
books
WHERE
--価格が3000円以上?
;
SELECT
isbn,
title,
publish,
price
FROM
books
WHERE
price >= 3000
;
Q1-3:前のページより
さらに出版社が「山田出版」「翔泳社」の
isbn、title、publish、price列を取り出せ。
SELECT
isbn,
title,
publish,
price
FROM
books
WHERE
--出版社が「山田出版」「翔泳社」
price >= 3000
;
SELECT
isbn,
title,
publish,
price
FROM
books
WHERE
publish IN ('山田出版','翔泳社')
AND
price >= 3000
;
Q2:アンケート回答テーブル(quest)から
性別が「女」であり、かつ、年齢が20歳代である
回答者の全列を取り出すSQL文を完成させろ。
SELECT
*
FROM
quest
WHERE
[①]
AND
[②]
;
SELECT
*
FROM
quest
WHERE
sex = '女'
AND
age BETWEEN 20 AND 29
;
Q3:ユーザテーブル(usr)から東京都在住で、
かつ、E-Mailアドレスのドメインが「examples.com」の
l_name、f_name、email列を取り出すSQL文を完成させろ。
SELECT
l_name,
f_name,
email
FROM
usr
WHERE
[①]
AND
[②]
;
SELECT
l_name,
f_name,
email
FROM
usr
WHERE
prefecture = '東京都'
AND
email LIKE '%examples.com'
;
Q4:アンケート回答テーブル(quest)から
感想欄が空でないもののanswer2列を取り出せ。
SELECT
answer2
FROM
quest
WHERE
answer2 IS NOT NULL
AND
感想欄が空でないもの
;
SELECT
answer2
FROM
quest
WHERE
answer2 IS NOT NULL
AND
answer2 <> ''
;
Q5:社員テーブル(employee)から
「山田奈美」さんの情報を取り出せ。
SELECT
*
FROM
employee
WHERE
'山田'
AND
'奈美'
;
SELECT
*
FROM
employee
WHERE
l_name = '山田'
AND
f_name = '奈美'
;
Q6:書籍情報テーブル(books)から
出版社(publish列)が「秀和システム」または「山田出版」、
かつ、価格(price列)が3000円未満の
isbn、title列を取り出すSQL文の誤りを正せ。
SELECT
isbn,
title,
publish,
price
FROM
books
WHERE
publish = '秀和システム'
AND
publish = '山田出版'
OR
price < 3000
;
SELECT
isbn,
title,
publish,
price
FROM
books
WHERE
(
publish = '秀和システム'
OR
publish = '山田出版'
)
AND
price < 3000
;
4.4正規表現の概念
正規表現(Regular Expression)は、文字列のパターンを定義するための特殊な記法です。特定の形式や規則に基づいて文字列を検索、マッチング、置換する際に利用されます。この機能はデータベースのクエリにおいて極めて役立ちます。
PostgreSQLでの正規表現の利点
- データの柔軟な検索: 正規表現を使用することで、データの特定のパターンを簡単にフィルタリングできます。これにより、部分一致や条件に応じた検索が行いやすくなります。
- 強力な文字列操作: 正規表現は、単純な文字列一致にとどまらず、複雑な条件を持つ検索も可能にします。
- データクレンジング: データエントリの検証やクリーニングの際にも正規表現を使用し、一貫したデータを保持するためのツールとして機能します。
正規表現の記号一覧
次に、PostgreSQLにおける正規表現の記号一覧を示します。これらを理解することで、パターンマッチングをより強力に活用できるようになります。
| 記号 | 説明 | 使用例 |
|---|---|---|
. | 任意の1文字にマッチ | a.bはacbやa1bにマッチ |
^ | 行の先頭にマッチ | ^abcはabcdeにマッチ |
$ | 行の末尾にマッチ | abc$はdeabcにマッチ |
* | 直前の文字が0回以上繰り返すにマッチ | ab*cはac, abc, abbcにマッチ |
+ | 直前の文字が1回以上繰り返すにマッチ | ab+cはabc, abbcにマッチ |
? | 直前の文字が0回または1回の出現にマッチ | ab?cはac, abcにマッチ |
{n} | 直前の文字がちょうどn回繰り返すにマッチ | a{2}はaaにマッチ |
{n,} | 直前の文字がn回以上繰り返すにマッチ | a{2,}はaa, aaaにマッチ |
{n,m} | 直前の文字がn回以上m回以下繰り返すにマッチ | a{1,3}はa, aa, aaaにマッチ |
[...] | 指定した文字のいずれか1文字にマッチ | [abc]はa, b, cにマッチ |
[^...] | 指定した文字以外の任意の1文字にマッチ | [^abc]はd, eにマッチ |
(abc) | “(abc)”というグループにマッチ(キャプチャ) | (abc)はabcdefの中のabcにマッチ |
| | OR条件(選択) | abc|defはabcやdefにマッチ |
\ | エスケープ文字(特殊文字を通常の文字として扱う) | \.は.という文字にマッチ |
\d | 任意の数字([0-9]と同義) | \dは半角数字にマッチ |
\D | 任意の非数字([^0-9]と同義) | \Dは非半角数字にマッチ |
\s | 任意の空白文字(スペース、タブ、改行など) | \sはスペースにマッチ |
\S | 任意の非空白文字 | \Sはa,1にマッチ |
\w | 任意の単語文字(アルファベット、数字、_) | \wはa,3,_にマッチ |
\W | 任意の非単語文字 | \Wは!,@にマッチ |
| 文字 | 正規表現 |
|---|---|
| ひらがな | [ぁ-んー] |
| カタカナ(全角) | [ァ-ンー] |
| カタカナ(半角) | [ア-ン゙゚] |
| 漢字 | [一-龠] |
| 半角数字 | [0-9] |
| 英語(小文字) | [a-z] |
| 英語(大文字) | [A-Z] |
| 記号 | [!”#$%&'()*+-.,\/:;<=>?@[\]^_`{|}~] |
| スペース(半角) | [ ] |
| スペース(全角) | [ ] |
正規表現の演算子は以下の3種類があります。それぞれの読み方を紹介します。
~チルダ
!エクスクラメーション・マーク(exclamation mark)
*アスタリスク
*正規表現は基本的には文字列の列に対して使います。
--大文字含まない az
SELECT 列 FROM 机 WHERE 列 ~ '正規表現';
--否定
SELECT 列 FROM 机 WHERE 列 !~ '正規表現';
--大文字小文字含める azAZ
SELECT 列 FROM 机 WHERE 列 ~* '正規表現';
--否定
SELECT 列 FROM 机 WHERE 列 !~ '正規表現';問題:書籍情報テーブル(books)から
publish列に’山田’が入る行を全て取得したい。
--正規表現を使ってみましょう
SELECT
*
FROM
books
WHERE
--ここを考えてみましょう
;SELECT
*
FROM
books
WHERE
--publish like '%山田%'
publish ~ '山田'
;問題:書籍情報テーブル(books)から
category_id列の末尾が1,3,4の全列を
取得する正規表現を考えよう。
--LIKE文を使うと以下のようになります。
SELECT
*
FROM
books
WHERE
--Hint [] $
category_id LIKE '%1'
OR
category_id LIKE '%4'
OR
category_id LIKE '%3'
;
--正規表現を使うと以下の書き方で取得できる。
SELECT
*
FROM
books
WHERE
--答え
category_id ~ '[134]$'
;問題:著者情報テーブル(author)から
name_kanaが6文字の全列を
取得する正規表現を考えよう
select
*
from
author
where
--Hint . $ ^ {} などを使います。
;
select
*
from
author
where
name_kana ~ '^.{6}$'
--name_kana ~ '^\w{6}$'
;
5 ORDER BY
RDBMSにおいて検索結果の表示順は保障されていません。
RDBMSの格納のアルゴリズムと、取り出す際のアルゴリズムによって決定されるためです。
表示順を指示するための命令が「ORDER BY 句」となります。
一般的にはソートすることをいいます。
Q1-1:アンケート回答テーブル(quest)より
感想欄(answer2)が
空でない回答を取り出せ。
SELECT
*
FROM
quest
WHERE
answer2 <> ''
AND
answer2 IS NOT NULL
;
Q1-2:前のページより
answer1、answer2列のみを
取り出せ。
SELECT
answer1,
answer2
FROM
quest
WHERE
answer2 <> ''
AND
answer2 IS NOT NULL
;
Q1-3:前のページの結果を、
評価(answer1)の低い順に並びかえろ。
SELECT
answer1,
answer2
FROM
quest
WHERE
answer2 <> ''
AND
answer2 IS NOT NULL
ORDER BY
answer1 ASC
;
Q2:書籍情報テーブル(books)から
価格が2500~3500円の範囲の
title、price列を価格が
安い順に取り出すSQL文を完成させろ。
SELECT
title,
price
FROM
books
WHERE
[①]
ORDER BY
[②]
;
SELECT
title,
price
FROM
books
WHERE
price BETWEEN 2500 AND 3500
ORDER BY
price ASC
;
Q3:ユーザテーブル(usr)から
東京都、千葉県、神奈川県に住んでいる人の、
l_name、f_name、prefecture列を
姓(カナ)、名(カナ)の昇順で
取り出すSQL文を完成させろ。
SELECT
l_name,
f_name,
prefecture
FROM
usr
WHERE
[①]
ORDER BY
[②]
f_name_kana ASC
;
SELECT
l_name,
f_name,
prefecture
FROM
usr
WHERE
prefecture IN ('東京都','千葉県','神奈川県')
ORDER BY
l_name_kana ASC,
f_name_kana ASC
;
Q4:貸し出し記録テーブル(rental)から
未返却で、貸出日が2012年12月1日より前の
貸し出し情報を貸出日の
新しい順で全列を取り出せ。
SELECT
*
FROM
rental
WHERE
returned = 0
AND
rental_date < '2012/12/01'
ORDER BY
rental_date DESC
;
Q5:アクセス記録テーブル(access_log)から
2012年3月分のアクセスログを
referer、ip_address列について降順で取り出す
SQL文の誤りを正せ。
SELECT
*
FROM
access_log
WHERE
access_date IN (‘2012/03/01’,’2012/03/31’)
ORDER BY
referer,
ip_address DESC
;
SELECT
*
FROM
access_log
WHERE
access_date BETWEEN '2012/03/01' AND '2012/03/31'
ORDER BY
referer DESC,
ip_address DESC
;
6 LIMIT
- PostgreSQLとMySQLでは、違いがあるので要注意。
- どこから、どこまでの指定方法が違う
MySQL:LIMIT 0,5 と記述
PostgreSQL:LIMIT 5 OFFSET 0 と記述
スキップする行数を0行と指定し、5行まで出力する意味となる。
- Oracleと、SQL ServerにはLIMIT句がない。
Oracle:ROWNUMという変数をWHERE句に記述する。
SQL Server:先頭からの行数を指定する場合は
SELECT TOP 5 * FROM テーブル名;
読み飛ばす必要がある場合は、ORDER BY句と組み合わせる必要があります。
ORDER BY カラム名
OFFSET 開始行
FETCH NEXT 出力行数 ROWS ONLY;
Q1-1:社員テーブル(employee)から
l_name、f_name、last_update列を
取り出せ。
SELECT
l_name,
f_name,
last_update
FROM
employee
;
Q1-2:前のページ結果を
last_update列の新しい順で並べろ。
SELECT
l_name,
f_name,
last_update
FROM
employee
ORDER BY
last_update DESC
;
Q1-3:前のページ結果より
先頭5行をとりだせ。
SELECT
l_name,
f_name,
last_update
FROM
employee
ORDER BY
last_update DESC
LIMIT
5
OFFSET
0
;
Q2:書籍情報テーブル(books)より
刊行日が列の新しいもの3件目から5件の
title、publish_date列を取り出す
SQL文を完成させろ。
SELEC
title,
publish_date
FROM
books
[ ① ]
publish_date DESC
LIMIT
[ ② ]
;
SELECT
title,
publish_date
FROM
books
ORDER BY
publish_date DESC
LIMIT
5
OFFSET
2
;
Q3:アンケート回答テーブル(quest)より
回答日時(answered)が
新しいものを先頭から10件の
name、answer1、answer2列を
取り出すSQL文を完成させろ。
SELECT
name,
answer1,
answer2
FROM
quest
ORDER BY
[ ① ]
LIMIT
10
[ ② ]
;
SELECT
name,
answer1,
answer2
FROM
quest
ORDER BY
answered DESC
LIMIT
10
OFFSET
0
;
Q4:貸し出し記録テーブル(rental)より
未返却(returned=0)で
貸出日(rental_date)が
古い順に先頭から5件の
user_id、isbn、rental_date列を取り出せ。
SELECT
user_id,
isbn,
rental_date
FROM
rental
WHERE
returned = 0
ORDER BY
rental_date ASC
LIMIT
5
OFFSET
0
;
Q5:アクセス記録テーブル(access_log)より
アクセス日時(access_date)の
新しい順に10件のpage_id、referer、ip_address列を
取り出すSQL文の誤りを正せ。
SELECT
page_id,
referer,
ip_address
FROM
access_log
ORDER BY
access_date ASC
LIMIT
0
OFFSET
10
;
SELECT
page_id,
referer,
ip_address
FROM
access_log
ORDER BY
access_date DESC
LIMIT
10
OFFSET
0
;
7 GROUP BY
- 格納されたデータをそのまま出力するのではなく、分析の過程で行われる特定の項目ごとの集計を求めるために使用します。
- 詳細なトランザクションデータから~毎の集計を求める時に使用されます。
- 集計関数と合わせて使用します。
- SUM、COUNT、AVG等
- Pythonではpandasによって行われることが多くありますが、数万件のデータからであればリソースも多く使わず可能ですが、数億件以上の桁になると大規模なリソースが必要になることが多く、データベースの集計機能を利用することが多くあることを覚えておきましょう。
Q1-1:書籍情報テーブル(books)から
publish、price列を
取り出せ。
SELECT
publish,
price
FROM
books
;
Q1-2:前ページの結果を
publishごとの
価格の平均値として取り出せ。
SELECT
publish,
AVG(price)
FROM
books
GROUP BY
publish
;
Q2:アンケート回答テーブル(quest)から
性別(sex)毎に
年齢の最大/最小値を求める
SQL文を完成させろ。
SELECT
[ ① ]
FROM
quest
[ ② ]
sex
;
SELECT
sex,
MAX(age),
MIN(age)
FROM
quest
GROUP BY
sex
;
Q3:アンケート回答テーブル(quest)から
都道府県、性別毎に
評価の平均を求めるSQL文を完成させろ。
SELECT
[ ① ]
FROM
quest
GROUP BY
[ ② ]
;
SELECT
prefecture,
sex,
AVG(answer1)
FROM
quest
GROUP BY
prefecture,
sex
;
Q4:月間売り上げテーブル(sales)で、
店舗別の累計売上を求めろ。
SELECT
s_id,
SUM(s_value)
FROM
sales
GROUP BY
s_id
;
Q5:書籍情報テーブル(books)で、
出版社ごとの
最も高い書籍価格を求めろ。
SELECT
publish,
MAX(price)
FROM
books
GROUP BY
publish
;
Q6:アクセス記録テーブル(access_log)から、
メニューコード(page_id)別の
アクセス数を求めるSQL文を正せ。
SELECT
page_id,
SUM(*)
FROM
access_log
ORDER BY
page_id
;
SELECT
page_id,
COUNT(*)
FROM
access_log
GROUP BY
page_id
;
8 AS 別名
- RDBMSでは、テーブルやビューで定義されている列名は、多くの場合英語で表現される場合が多いようです。これは、システム内部でプログラムなどが扱うには適していますが、検索結果を帳票などにする場合、人にとっては分かりやすいものではありません。
- 人にとって分かりやすくするための機能を実現したのが、別名をつける事です。
Q1-1:書籍情報テーブル(books)から
書名(title)、
税込み価格(price*1.10)を
取り出せ。
SELECT
title,
price * 1.1
FROM
books
;
Q1-2:titleとprice*1.10と
表示されているところを
書名、税込み価格として取り出せ。
SELECT
title AS 書名,
price * 1.1 AS 税込み価格
FROM
books
;
Q2:商品テーブル(product)から
p_name、price列を
価格が安い順に取り出し、
列名を「商品名」「価格」として
取り出すSQL文を完成させろ。
SELECT
[ ① ],
[ ② ]
FROM
product
ORDER BY
price ASC
;
SELECT
p_name AS 商品名,
price AS 価格
FROM
product
ORDER BY
price ASC
;
Q3:アンケート回答テーブル(quest)から
都道府県名ごとの
回答者の平均年齢を求める
SQL文を完成させろ。
SELECT
[ ① ]
FROM
quest
GROUP BY
[ ② ]
;
SELECT
prefecture AS 都道府県名,
AVG(age) AS 平均年齢
FROM
quest
GROUP BY
都道府県名 --prefecture
;
Q4:ユーザテーブル(usr)から
都道府県別のユーザ数を
列名を「都道府県名」「ユーザ数」として求めよ。
SELECT
prefecture AS 都道府県名,
COUNT(*) AS ユーザ数
FROM
usr
GROUP BY
prefecture
;
Q5:書籍情報テーブル(books)から
出版社(publish)ごとの
書籍価格(price)の平均値を求めよう。
列名は「出版社」「価格平均」とする。
SELECT
publish AS 出版社,
AVG(price) AS 価格平均
FROM
books
GROUP BY
publish
;
Q6:アンケート回答テーブル(quest)から
都道府県(prefecture)、
性別(sex)ごとの
評価平均を求めるSQL文を正せ。
SELECT
prefecture,
sex,
age,
AVG(answer1) IS 評価平均
FROM
quest
GROUP BY
prefecture,
sex
;
SELECT
prefecture AS 都道府県名,
sex AS 性別,
AVG(answer1) AS 評価平均
FROM
quest
GROUP BY
prefecture,
sex
;
9 文字列/日付関数 加工
- 検索結果の文字列や、日時型の表示を加工することができます。
- SQLの方言がある部分ですので、RDBMS毎のマニュアルを確認しましょう。
文字列の単純結合は、PostgreSQLでは、
‘文字列’||’文字列’とすることが一般的だが
CONCAT(‘文字列’,’文字列’)と記述も可能です。
MySQLでは、
CONCAT(‘文字列’,’文字列’)と記述します。
PostgreSQLで利用可能な算術関数(一部抜粋)
| 関数 | 戻り値型 | 説明 | 例 | 結果 |
| abs(x) | (入力と同じ) | 絶対値 | abs(-17.4) | 17.4 |
| ceil(dp or numeric) | (入力型と同一) | 引数より小さくない最小の整数 | ceil(-42.8) | -42 |
| ceiling(dp or numeric) | (入力型と同一) | ceilの別名 | ceiling(-95.3) | -95 |
| floor(dp or numeric) | (入力型と同一) | 引数より大きくない最大の整数 | floor(-42.8) | -43 |
| round(dp or numeric) | (入力型と同一) | 四捨五入 | round(42.4) | 42 |
演算子、関数ついてはバージョン15の日本語マニュアル
https://www.postgresql.jp/docs/15/functions-math.html
https://www.postgresql.jp/docs/9.4/functions-string.html
を参照してください。
Q1-1:書籍情報テーブル(books)から
ISBNコード(isbn)、
書名(title)、
刊行日(publish_date)を取り出せ。
SELECT
isbn,
title,
publish_date
FROM
books
;
Q1-1:前頁の結果に
ISBNコード(isbn)の頭に
一律「ISBN」という固定文字列を付加し、
刊行日(publish_date)は
「YYYY年MM月DD日」の形式に整形せよ。
SELECT
'ISBN'||isbn,
title,
TO_CHAR(publish_date,'YYYY年MM月DD日')
FROM
books
;
Q2:アンケート回答テーブル(quest)から
都道府県別の評価の平均値を
小数点以下を四捨五入して
取り出すSQL文完成させろ。
SELECT
prefecture,
[ ② ] AS 評価平均
FROM
quest
GROUP BY
[ ② ]
;
SELECT
prefecture,
ROUND(AVG(answer1)) AS 評価平均
FROM
quest
GROUP BY
prefecture
;
Q3:貸し出し記録テーブル(rental)から
未返却の書籍情報を抽出するSQL文を完成させろ。
抽出列はisbn、rental_dateとし、
別名を「ISBNコード」、「貸出日」とし、
形式をYY/MM/DDとする。
SELECT
isbn AS ISBNコード,
[ ② ]
FROM
rental
WHERE
returned = 0
[ ② ]
rental_date ASC
;
SELECT
isbn AS ISBNコード,
TO_CHAR(rental_date,'YY/MM/DD') AS 貸出日
FROM
rental
WHERE
returned = 0
ORDER BY
rental_date ASC
;
Q4:ユーザテーブル(usr)から
利用者(氏名)(l_name、f_name)と
完全な住所(prefecture、city、o_address)を
利用者コード(user_id)の降順で取り出せ。
SELECT
l_name||f_name AS 利用者(氏名),
prefecture||city||o_address AS 住所
FROM
usr
ORDER BY
user_id DESC
;
Q5:書籍情報テーブル(books)から
出版社ごとの
書籍価格の平均値を
小数点以下を切り捨てて取り出せ。
SELECT
publish,
FLOOR(AVG(price))
FROM
books
GROUP BY
publish
;
Q6:社員テーブル(employee)から
部署、役職ごとに
降順で取り出す
SQL文の誤りを正せ。
SELECT
depart_id,
class,
‘l_name’||‘f_name’ AS 氏名
FROM
employee
ORDER BY
depart_id,
class DESC
;
SELECT
depart_id,
class,
l_name || f_name AS 氏名
FROM
employee
ORDER BY
depart_id DESC,
class DESC
;
10 HAVING
- GROUP BY句と組み合わせて使用します。
- WHERE句では判定できない、集計関数を使った条件に使用します。
Q1-1:アンケート回答テーブル(quest)から
都道府県(prefecture)ごとの
評価平均(answer1の平均)を取り出せ。
SELECT
prefecture,
AVG(answer1) AS 評価平均
FROM
quest
GROUP BY
prefecture
;
Q1-2:前頁の結果から
評価平均が2未満のものに絞り込もう。
SELECT
prefecture,
AVG(answer1) AS 評価平均
FROM
quest
GROUP BY
prefecture
HAVING
AVG(answer1) < 2
;
Q2:アンケート回答テーブル(quest)から
都道府県ごとの
年齢の平均が35歳以上50歳未満のデータだけを
取り出すSQL文完成させろ。
SELECT
[ ① ]
FROM
quest
GROUP BY
prefecture
HAVING
[ ② ]
;
SELECT
prefecture,
AVG(age)
FROM
quest
GROUP BY
prefecture
HAVING
AVG(age) BETWEEN 35 AND 49
;
Q3:アンケート回答テーブル(quest)から
都道府県ごとに
男性回答者のみの
年齢の最高値が60歳より大きいデータだけを
取り出すSQL文を完成させろ。
SELECT
[ ① ]
FROM
quest
[ ② ]
sex='男'
GROUP BY
prefecture
[ ③ ]
MAX(age)>60
;
SELECT
prefecture, MAX(age)
FROM
quest
WHERE
sex='男'
GROUP BY
prefecture
HAVING
MAX(age)>60
;
Q4:書籍情報テーブル(author_books)から
著者(author_id)ごとの
書籍(isbn)数が
3冊以上の情報を取り出せ。
SELECT
author_id,
COUNT(isbn)
FROM
author_books
GROUP BY
author_id
HAVING
COUNT(*) >= 3
;
Q5:書籍情報テーブル(books)から
出版社(publish)、
分類ID(category_id)ごとに
登録数を求め、
登録数が3冊未満の情報を取り出せ。
SELECT
publish,
category_id,
COUNT(*)
FROM
books
GROUP BY
publish,
category_id
HAVING
COUNT(*) < 3
;
Q6:社員テーブル(employee)から
部署(depart_id)ごとの
女性の人数が3人以上の部署だけを
出力するためのSQL文を正せ。
SELECT
depart_id,
COUNT(*)
FROM
employee
WHERE
sex = 2
ORDER BY
depart_id
WHERE
COUNT(*) >= 3
;
SELECT
depart_id,
COUNT(*)
FROM
employee
WHERE
sex = 2
GROUP BY
depart_id
HAVING
COUNT(*) >= 3
;
Q7:アクセス記録テーブル(access_log)から
アクセス日付(access_date)が
2013/01/01以降のものについて
リンク元URL(referer)ごとの
アクセス数が5件未満のデータだけを
アクセス数を降順で取り出すSQL文完成させろ。
SELECT
referer,
[ ① ]
FROM
access_log
WHERE
[ ② ]
GROUP BY
referer
[ ③ ]
[ ① ] < 5
ORDER BY
[ ① ] [ ④ ]
;
SELECT
referer,
COUNT(*)
FROM
access_log
WHERE
access_date >= '2013/01/01'
GROUP BY
referer
HAVING
COUNT(*) < 5
ORDER BY
COUNT(*) DESC
;
11 CASE 演算子
- 検索結果の加工に使用します。
- CASE式には単純CASE式と検索CASE式があります。
CASE
answer1
WHEN 3 THEN 'ためになった'
WHEN 2 THEN '普通'
WHEN 1 THEN '役に立たない'
ELSE ''
END- 上記(単純CASE式)のように、答えが3ならば「ためになった」のように検索結果を変更するためには便利な機能です。
Q1-1:アクセス記録テーブル(access_log)から
リンク元(referer)ごとのアクセス数を取り出せ。
SELECT
referer,
COUNT(*)
FROM
access_log
GROUP BY
referer
;
Q1-2:前頁の結果から
リンク元(referer)ごとの
アクセス数をカウント数として別名をつけ、
ランクA(50件以上)、
B(1件~49件)、
C(10件未満)
として表示せよ。
SELECT
referer,
count(*) AS カウント数,
CASE
WHEN count(*) >= 50 THEN 'A'
WHEN count(*) >= 10 THEN 'B'
ELSE 'C'
END AS ランク
FROM
access_log
GROUP BY
referer
;
Q2:アンケート回答テーブル(quest)から
回答日時が新しい順に
name別名「氏名」、
answer1別名「評価」、
answer2別名「感想」列を
取得するSQL文を完成させろ。
SELECT
name AS 氏名,
[ ① ],
[ ② ]
FROM
quest
ORDER BY
[ ③ ]
;
SELECT
name AS 氏名,
answer1 評価,
answer2 感想
FROM
quest
ORDER BY
answered DESC
;annswer1の値3~1に対し
「ためになった」
「普通」、
「役に立たない」
と置き換えよう。
SELECT
name AS 氏名,
CASE
answer1
WHEN 3 THEN 'ためになった'
WHEN 2 THEN '普通'
WHEN 1 THEN '役に立たない'
ELSE ''
END AS 評価,
answer2 AS 感想
FROM
quest
ORDER BY
answered DESC
;
Q3:貸し出し記録テーブル(rental)からISBNコード(isbn)でグループ化し、
それぞれの「貸出数」列を出力し、
貸出数が10以上ならば「好評」、
5以上10未満なら「普通」、
5未満なら「不評」
とする「評価列」取り出すSQL文を完成させろ。
SELECT
isbn,
[ ① ],
CASE
[ ② ] COUNT(*) >= 10 [ ③ ] ‘好評’
[ ② ] COUNT(*) >= 5 [ ③ ] ‘普通’
ELSE ‘不評’
END AS 評価
FROM
rental
[ ④ ]
isbn
;
SELECT
isbn,
COUNT(*) AS 貸出数,
CASE
WHEN COUNT(*) >= 10 THEN '好評'
WHEN COUNT(*) >= 5 THEN '普通'
ELSE '不評'
END AS 評価
FROM
rental
GROUP BY
isbn
;
Q4:アクセス記録テーブル(access_log)から
リンク元(referer)ごとのアクセス数を求め、
アクセス数が3件以上のものを多い順に抽出し、
アクセス数が10未満ならば「C」、
10件以上50件未満を「B」、
50件以上を「A」
とする「ランク」列を取り出せ。
SELECT
referer AS リンク元,
count(*) AS アクセス数,
CASE
WHEN COUNT(*) < 10 THEN 'C'
WHEN COUNT(*) < 50 THEN 'B'
ELSE 'A'
END AS ランク
FROM
access_log
GROUP BY
referer
HAVING
COUNT(*) >= 3
ORDER BY
COUNT(*) DESC
;
Q5:著者-書籍情報テーブル(author_books)から
著者ID(author_id)ごとの書籍数を「カウント数」、
書籍数が4冊以上のもの「多い」、
2冊以上4冊未満を「普通」
2冊未満を「少ない」
とし「評価」列を取り出せ。
SELECT
author_id AS 著者ID,
COUNT(*) AS カウント数,
CASE
WHEN COUNT(*) >= 4 THEN '多い'
WHEN COUNT(*) >= 2 THEN '普通'
ELSE ''
END AS 評価
FROM
author_books
GROUP BY
author_id
;
Q6:社員テーブル(employee)から
社員名「氏(l_name)+名(f_name)を連結する」、
役職クラス「
部長、課長は管理職、
主任、担当は総合職に、
アシスタントは一般職
」
を取り出すSQL文の誤りを正せ。
SELECT
CONCAT(l_name,f_name),
CASE
WHERE class IN ('部長','課長') THEN '管理職'
WHERE class IN ('主任','担当') THEN '総合職'
ELSE '一般職'
END AS 役職クラス
FROM
employee
;
SELECT
CONCAT(l_name,f_name) AS 社員名,
CASE
WHEN class IN ('部長','課長') THEN '管理職'
WHEN class IN ('主任','担当') THEN '総合職'
ELSE '一般職'
END AS 役職クラス
FROM
employee
;


コメント